淘宝运营,站内搜索指南之千人千面v兔电商工具
站内搜索怎样玩转个性化千人千面
个性化千人千面其实在电商站内搜索领域,其核心的机密基本上就属于排序算法范围内了。我在上一章节中夸下海口说要给大家唠一唠电商算法的形成的过程,其实是有点心虚的,因为我压根不是算法出身,也无法给大家讲解什么拉格朗日公式的原理,贝叶斯的变形公式等。但是我能给大家解释一下这些算法的形成过程,以及在形成过程中运营和产品是如何配合的,以及如何运用一个现成的方案,开发出一套高时间性价比的搜索产品体系。
电商站内搜索其实是以算法为核心,运营为辅助的模块。说到底,如果搜不准,搜不全,运营的再好也只是空中楼阁,因此我们先讲一讲算法体系,再讲运营方式。
那如果是我,如何从0起步建立起一套经济实惠,省时省力的搜索逻辑体系(也有可能是我闭门造车,所以谨慎采纳,不喜请诚恳地指正)。
说句题外话: 算法听上去高大上,其实通俗地讲,就是解决问题的方法,即便是计算公式再高大上,技术理念再先进,如果解决不了问题,一样不能叫算法。
其次很多人以为算法其实应该是纯计算机来解决,其实这是一种误解,不可否认,计算机自动化确实是在算法中占举足轻重的地位,但是算法不仅仅是计算机,还有人工积累的比重,且不可或缺。
因此搜索算法也一样,离开了人工辅助,算法什么问题都解决不了。好了说正经的,搜索算法主要分为以下几个核心:
- 分词算法
- 类目预测算法(解决准不准的基础)
- 商品排序算法(电商核心机密)
- 个性化千人千面(电商数据提升机密)
分词算法
我们先来了解下分词算法:目前国内有专门的汉语分词第三方分词接口,且功能完善,成本低廉,能够进行词干提取,语义分析,甚至情感判断等。算法方面也是百花齐放,各有优劣,目前有三大主流分词方法:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。
基于字符串匹配的分词方法
又称为机械分词方法,它需要有一个初始的充分大的词典,然后将待分词的字符串与词典中的元素进行匹配,若能成功匹配,则将该词切分出来。
按扫描方向的不同,字符串匹配分词方法可以分为正相匹配和逆向匹配;按照不同长度的匹配优先度可以划分为最大匹配和最小匹配(细节我就不在这说了,这种分词方式是属于最为简单分词方式,可以自行百度其工作逻辑和流程).
基于理解的分词方法
这个就有点技术含量,国内的主要搜索大厂,比如百度、字节跳动等都在开发带有人工智能模块的搜索算法。其基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。它通常包括三个部分:分词子系统、句法语义子系统、总控部分。
由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式,因此目前基于理解的分词系统还处在验证和试用型阶段。
基于统计的分词方法
即每个字都是词的最小单元,如果相连的字在不同的文本中出现的频率越多,这就越有可能是一个词。因此我们可以用相邻字出现的频率来衡量组词的可能性,当频率高于某个阈值时,我们可以认为这些字可能会构成一个词。
主要统计模型: N元文法模型(N-gram),隐马尔可夫模型(Hidden Markov Model,HMM),最大熵模型(ME),条件随机场(Conditional Random Fields,CRF)等。
优势:在实际运用中常常将字符串匹配分词和统计分词结合使用,这样既体现了匹配分词速度快、效率高的优点,同时又能运用统计分词识别生词、自动消除歧义等方面的特点。
基于统计的分词方式&类目预测
我们着重了解一下第三种,基于统计的分词方式&类目预测。如果说有什么算法是基于统计的,那么这个算法肯定需要一个训练集,而且这个训练集需要是正确的,人为校验的。
因此我们所说的这种算法,则是在人工标注的训练集上训练而成的。因此我们接下来将要讨论的算法是——类目预测训练集。
目前从训练集上来看,收集的方式主要有两种,第一种是人工中心词收集,第二种则是机器分析与训练。
人工中心词收集
这个方案其实是比较讨巧的,基于规范的词典词语来进行收集,主要收集物品词&品牌词。
之所以要选定物品和品牌词收集还是基于上一章提过的app购物行为假设,即用户在购物app中始终是以搜索物品或者品牌的型号/物品为最终目的。
如果用户进入app不进行物品词或者品牌词搜索,这个用户对该app而言的价值显然会大打折扣,也许有的人会说,每天搜索的人那么多,保不齐会有人搜索比较范范的词,那不算吗。其实是算的,但是我们现在讲得是基于统计概率来说,如果95%的人都搜索物品和品牌,那么你现在纠结5%的人不是这样的情况显然是没有意义的。还是那句话,越是想两全,越是两遍都不全。好了,言归正传。收集的流程如下图:
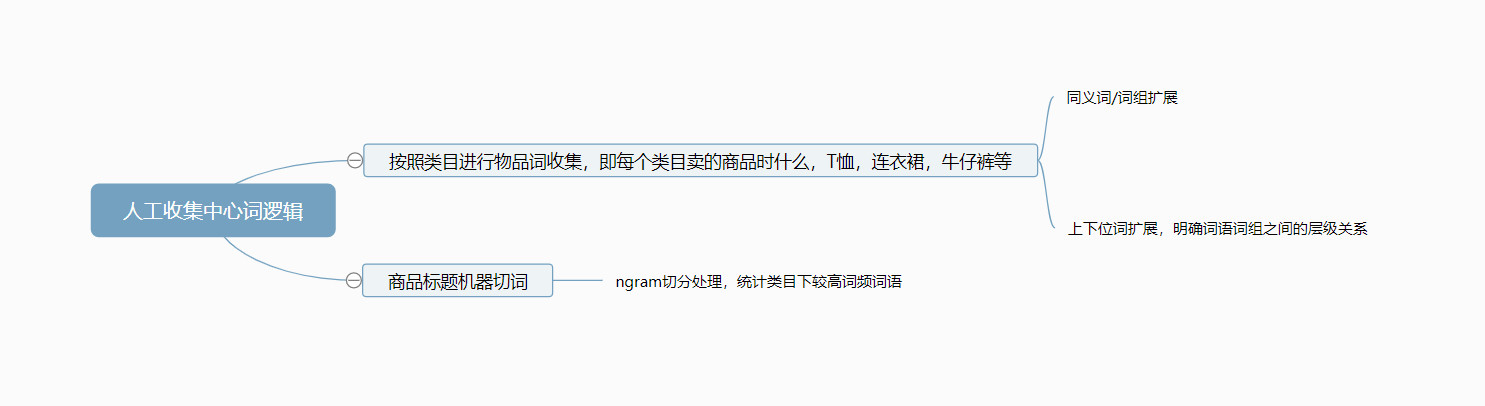
道理很简单,即通过收集站内每个类目所售卖的物品,同时通过拓展这些物品词的同义词和上下位词,来对应这些类目。同时机器也可以通过算法来进行收集,对所有商品标题进行ngram统计切分,统计出每个类目出现频率最多的词和词组等,与人工收集的相对照进行检验和补充。这样我们就得到了一个物品词-类目的对应表。一个简单高效的训练集就诞生了。
那么肯定有人会说“也不行啊,你光收集物品词了,还有氛围词、人群词呢?比如学校、工地、男士、女士你都不收集了,男士鞋子你怎么办?”
当然不是,这个物品-类目词的对应表训练集只是个基础。只有在保证训练集非常准确且覆盖面全的情况下,才能确保机器进行训练,且即便我仅仅是打个基础,也能比较正确的召回,你是不是忽略了全词匹配的作用了?
在物品词训练集整理好之后。接下来可以开始对用户关键词开始分析了,即通过用户输入的关键词统计点击行为,描述这些点击落在哪些类目的概率,并分析这些关键词和训练集中的物品/品牌型号词的类目关系,进一步进行人工校对和遍历。
这样就得到了一个用户行为和网站商品数据的合集训练集,在经过人工校对后就形成了一个准确性好,覆盖面高的训练集。此时经过不断的人工校对-机器训练-再校对-再训练的过程,直至想要达到的效果。一个类目预测算法就此诞生(以上你们看看就好,当我自嗨好了)。
机器训练需要切实的关键词进行离线训练和离线评估,以及在线ab和数据评估。前者是自己在离线环境下,使用用户输入的关键词进行训练并离线人工评估准确度;后者则是将训练好的模型上线,采用ab测的方式,开一部分小流量进行在线实战测试,并通过收集测试组的数据指标评估和分析效果。这也是互联网产品迭代最主要的测试方式之一。
类目预测的人工和机器算法相结合的算法大概就是这样,其实还有其他便捷的途径,就是逻辑没有以上这个清晰,所以我就不单列出来了。
商品排序算法
基本的类目排序逻辑确定好之后,我们其实会发现,用户的关键词其实是一个巨大的行为数据宝库,用户从输入关键词那一刻起,从点击商品,到收藏,到加入购物车,到购买行为等,都能透露出其购物偏好。
如何将这些行为有效的记录并训练起来也能对商品的排序准确性和购买率起着较大的影响,其实目前各大网站的推荐算法还是有一些问题的,比如我前几天在淘宝上买了一台电视,结果接下来的日子里我的首页都充斥着各种电视的图片,以及链接的外部DSP广告也给我推送电视的信息(这就是侵犯个人隐私的大数据统计算法所为)。
商品排序算法的轮廓我已经在之前的章节提及,各种维度我就不再赘述,只说说这种排序权重计算规则的由来,一言以蔽之就是不断调整每个维度权重的数值,并上线ab测试,以产出比最高的一组作为最终的算法排序规则。
当然这一规则和算法并不是恒定不变的,是随着维度的不断丰富和数据变化不停调整的。
个性化千人千面
现在各家网站都讲求个性化千人千面,这也是我们看到京东、淘宝、苏宁等电商首页时,其个性化推荐模块给你推荐你曾经看到过或者似曾相似的商品。并不是他们聪明了,而是你的行为被收集处理过了,展现给你的,就是你想看的,或者说想买的。(钱包也是这样被掏空的)
好了,这期就到这吧。其实我有挺多关于人工和机器算法的结合的想法和尝试,只不过在和工作中的同事交流时,因为各种原因未能付诸实践,我将其保留在自己的OneNote笔记中。有机会分享给大家。
v兔电商工具,详情: http://ask.vv-tool.com/- 发表于 11/13/2020 22:54:42
- 阅读 ( 865 )
- 分类:运营推广
